In this post I would like to continue my thoughts on understanding linear structure of data, by describing the popular linear algebraic technique used to discover linear structure, namely Singular Value Decomposition. Then I would like to give you a basic collaborative filtering algorithm based on the SVD than can be used to make recommendations to customers based on their prior purchases or revealed preferences.
Recall that our data matrix  is of dimension
is of dimension  where each column
where each column  corresponds to a unique customer and describes his/her likes or dislikes for the
corresponds to a unique customer and describes his/her likes or dislikes for the  items for sale in the store, indexed by
items for sale in the store, indexed by  . The question we asked was: Do these
. The question we asked was: Do these  vectors lie close to, on in, some
vectors lie close to, on in, some  dimensional subspace of the dimensional space where the data vectors reside? To answer this question, we perform a Singular Value Decomposition of the data matrix as follows:
dimensional subspace of the dimensional space where the data vectors reside? To answer this question, we perform a Singular Value Decomposition of the data matrix as follows:

Don’t worry just now about how this decomposition is achieved, just be assured that such a decomposition is always possible, and can can be done by making a simple function call in any numerical computation package like Python-Numpy, R, or Matlab.
Let us look at the decomposed matrices a little bit. The matrix  is an diagonal matrix, meaning that it does not have any non-zero values off-diagonal. The values on the diagonal are guaranteed to be non-negative and are called the singular values of the data matrix . By convention they are organized in decreasing magnitude as we go down the diagonal.
is an diagonal matrix, meaning that it does not have any non-zero values off-diagonal. The values on the diagonal are guaranteed to be non-negative and are called the singular values of the data matrix . By convention they are organized in decreasing magnitude as we go down the diagonal.
The matrices  and
and  are of dimension
are of dimension  and
and  respectively. I will now talk only about the matrix because that is enough for our current purpose, but keep in mind that all the properties of are also symmetrically true for .
respectively. I will now talk only about the matrix because that is enough for our current purpose, but keep in mind that all the properties of are also symmetrically true for .
The matrix is orthonormal, which means that

The geometric interpretation of this is that the columns of are all of unit length and are all orthogonal (perpendicular) to each other. Each column is called a (left) singular vector and specifies a direction in the dimensional space. Together these singular vectors form a cartesian coordinate system for the space where the data vectors live. That is, the dimensional data space is spanned by the columns of and every data vector can be expressed as a linear combination of the column vectors of .
The column vectors of are in on-to-one correspondence with the singular values. So the first column of corresponds to the first singular value on the diagonal of , the second column corresponds to the second singular value on the diagonal of , and so on.
The singular values capture the average behavior of the data in terms of energy distribution. The magnitude of a singular value tells us how important, on average, is the direction specified by the corresponding column of for the composition of the data, in terms of the energy of each data vector. Naturally, since we kept the biggest singular values on top of the diagonal of , the left most columns of are the most important directions in the data space, and the sub-space spanned by these left-most columns forms the dominant subspace of the data. Conversely if some of the singular values are very small, say even zero, it means that none of the energy of the data vectors resides in the sub-space spanned by the corresponding columns/singular vectors.
So you must have guessed by now that finding the dominant subspace is nothing but finding the significant singular values of and then picking out the corresponding singular vectors from . Suppose there are  significant/dominant singular values. As I said last time, if is much smaller than (written as
significant/dominant singular values. As I said last time, if is much smaller than (written as  ), it means that most of the energy of the data is located in a relatively small dimensional subspace, or in other words, the data lives close to a small dimensional subspace, and hence is said to have significant linear structure. Let
), it means that most of the energy of the data is located in a relatively small dimensional subspace, or in other words, the data lives close to a small dimensional subspace, and hence is said to have significant linear structure. Let  be the
be the  dimensional matrix formed by taking the leftmost singular vectors in that span the dominant subspace. This is an important matrix that we will now use to do some cool stuff.
dimensional matrix formed by taking the leftmost singular vectors in that span the dominant subspace. This is an important matrix that we will now use to do some cool stuff.
So now that we know how to find linear structure, how do we use this knowledge to make recommendations? So suppose a new customer comes along and shows his likes and dislikes for a few of the items in the store. Let this preference vector be  . Recall that for the items for which the customer did not express any preference, we do not use the value
. Recall that for the items for which the customer did not express any preference, we do not use the value  but rather a special symbol NA. We want to take this incomplete vector and, in some sense, complete it by putting the most reasonable numbers in place of the NA symbols. Then perhaps we can send out an email to the customer with advertisement about our stock of those of the NA items that we estimate the customer will have a high preference for. Or perhaps we can offer the customer a discount on those items to nudge him into making the purchase. (Whether every customer will like this kind of “mind reading” is still a hotly debated issue, and I am not qualified to speak about the efficacy of this approach in terms of customer psychology. For those of you interested in this topic I would recommend that you Google the term “uncanny valley”!)
but rather a special symbol NA. We want to take this incomplete vector and, in some sense, complete it by putting the most reasonable numbers in place of the NA symbols. Then perhaps we can send out an email to the customer with advertisement about our stock of those of the NA items that we estimate the customer will have a high preference for. Or perhaps we can offer the customer a discount on those items to nudge him into making the purchase. (Whether every customer will like this kind of “mind reading” is still a hotly debated issue, and I am not qualified to speak about the efficacy of this approach in terms of customer psychology. For those of you interested in this topic I would recommend that you Google the term “uncanny valley”!)
So how do we do the recommendation? The answer is pretty simple: Simply “pull” the vector down into the most optimal location inside the subspace spanned by . In doing so, the NA locations in the vector will develop some positive or negative numbers, which we read off as the estimated preferences for those items. Mathematically speaking, the algorithm works like this:
- Put value in every NA location of , while keeping a record of the indices of those locations. Call this vector
 .
.
- (Projection step:) Project into the dominant subspace by the operation:

- (Imputation step:) Put the values from
 , corresponding to the NA locations, into the vector while retaining the truly known value in .
, corresponding to the NA locations, into the vector while retaining the truly known value in .
- Repeat Projection and Imputation steps (2,3) till convergence, meaning does not change appreciably any further.
(These type of loopy algorithms are called iterative.) The values developed in the NA locations in are our estimated preferences or “recommendations”.
Those of you who have been reading carefully should now ask the question: “But in order to get the subspace you assumed that we could do the SVD algorithm on a fully known data matrix . But what about when there are unknown values in the data matrix itself, how can we do SVD then?” The answer is that, similar to the recommendation algorithm for a new customer described above, we also need to do an iterative “imputed” SVD calculation when the data matrix has unknown values. Basically, we take the data matrix, put in zeros for NA values, do SVD, then impute the NA values while leaving the true value intact, and iterate this procedure till convergence.
Anyway, I think that is enough math for today. I have already exceeded the amount I had intended to introduce for this topic! But perhaps this effort will pay off later, because many of the things I want to talk about, like the algebraic structure or “source codes” of discrete valued data (like color of hair, ethnicity)) as well as non-linearstructure and manifolds for continuous valued data (like photographs or seismic signals), have beautiful connections to, and generalizations from, the basic ideas of linear analysis in real vector spaces.
The main theme you should take away from today is this: Structure in data implies mutual information among its various components. Such structure is generically described by a set of parameters or “a model”, and it is “learnt” by processing archival “training” data. (The linear structure, for example, was described by the parameter and was learnt by SVD analysis of the data matrix.) The learnt model can then be used to predict one variable or set of variables of the data by observing another variable or set of variables. This is, ultimately, all that machine learning is all about!
 apps/items. At the same time the number of users
apps/items. At the same time the number of users  . Then we ask ourselves, is their significant mutual information between two subsets of these variables, say
. Then we ask ourselves, is their significant mutual information between two subsets of these variables, say 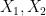 and
and 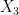 , and can we predict
, and can we predict  dimensions (many of us even have difficulty in
dimensions (many of us even have difficulty in 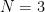 dimensions), just consider
dimensions), just consider 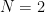 dimensions. That is, think of our data points as scattered on a sheet of plain white paper, where the origin of the coordinate system is in the center of the page and
dimensions. That is, think of our data points as scattered on a sheet of plain white paper, where the origin of the coordinate system is in the center of the page and  passing through the origin? We could “eye-ball” whether this property is true by holding a ruler flat on the paper with its edge passing through the origin, and rotating it about the origin till we suddenly see most of the data points lying close to the ruler’s edge. Would this structure suggest mutual information and hence predictability of
passing through the origin? We could “eye-ball” whether this property is true by holding a ruler flat on the paper with its edge passing through the origin, and rotating it about the origin till we suddenly see most of the data points lying close to the ruler’s edge. Would this structure suggest mutual information and hence predictability of 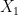 from
from 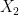 ? If you think about this for a moment, you will see that the answer is yes.
? If you think about this for a moment, you will see that the answer is yes. of the r.v.
of the r.v.  to the line
to the line 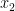 of
of  on a PC in a matter of minutes.
on a PC in a matter of minutes. when the data is of high dimension like
when the data is of high dimension like  , then you have a windfall on your hand. You can get a lot of mileage with very little effort!
, then you have a windfall on your hand. You can get a lot of mileage with very little effort!